자 드디어 Batch 성능 향상을 위한 CustomItemReader를 만들어보자.
우선 CustomItemReader를 만들려는 이유를 다시 생각해 보면 기존에 사용하던JpaRepositoryItemReader에선 대용량 Data를 Read 할 때 Paging 방식이 Offset을 사용하는 방식이기 때문에 (사용 Database에 따라 다르다) Data 양이 많아질수록 Data를 Read 하는 속도가 많이 늘어나게 된다.
그렇다면 해결 방법은 Offset을 사용하지 않고 대용량 Data를 Read하는 것
바로 Table에 ID 값을 이용하여 Read하는 것이다.
바로 코드부터 보자면.
(실사용 코드가 아니므로 오타가 있을 수 있음)
@Slf4j
public class CustomMemberReader extends AbstractPagingItemReader<MemberDto> {
private final EntityManager entityManager;
private Long lastId;
public CustomGasInspectionMeterReader(EntityManager entityManager, int pageSize, Long lastId) {
this.entityManager = entityManager;
this.lastId = lastId;
setPageSize(pageSize);
setName(ClassUtils.getShortName(CustomMemberReader.class));
}
@Override
protected void doReadPage() {
JPAQueryFactory queryFactory = new JPAQueryFactory(entityManager);
JPAQuery<GasInspectionMeterDto> query = queryFactory
.select(Projections.constructor(
MemberDto.class,
member.id,
member.name,
member.age
))
.from(member)
.where(member.deleted.isFalse()
.and(containLastId(lastId)))
.orderBy(member.id.asc())
.limit(getPageSize());
super.results = query.fetch();
findMaxId(super.results);
}
private void findMaxId(List<MemberDto> dtos) {
for (MemberDto dto : dtos) {
Long memberId = dto.getMemberId();
if (memberId != null && (lastId == null || memberId > lastId)) {
lastId = memberId;
}
}
}
private BooleanExpression containLastId(Long lastId) {
if (lastId != null) {
return member.id.gt(lastId);
}
return member.id.gt(0);
}
}
첫번째. 우선 Class
AbstractPagingItemReader를 상속받았다.
AbstractPagingItemReader를 상속받으면 doReadPage를 필히 구현해야 한다.
따라서 doReadPage() 메서드를 Override 해준다.
다음 CustomItermReader에는 사용할 EntityManager와 lastId를 필드로 선언한다.
EntityManger는 변하지 않으므로 final로 선언하고 lastId는 뒤에서 유동적으로 변하기 때문에 final을 제외했다.
두 번째. 생성자
생성자는 EntityManager, pageSize, lastId 총 3개의 값을 전달받아 생성된다.
생성자가 생성될 때 상위 클래스의 setPageSize()를 이용하여 전달받은 pageSize로 Set 하게 된다.
setName 또한 동일하게 적용한다.
세 번째. Override 한 doReadPage()
doReadPage에선 별 거 없다.
본인이 Read 하고자 하는 쿼리를 JPAQueryFactory를 이용하여 잘 작성해 주면 된다.
자세히 볼 곳은 where절이다.
where 절의 containLastId()를 살펴보면
private BooleanExpression containLastId(Long lastId) {
if (lastId != null) {
return member.id.gt(lastId);
}
return member.id.gt(0);
}
lastId가 null이면 member.id > 0 이라는 조건을 넘기고 null이 아닐 시엔 member.id > lastId 라는 값을 넘긴다.
(여기서 감이 올 수도 있다. 똑똑하네 자네)
그리고 orderBy도 중요
다음은 super.results 에 본인이 Query로 select한 값을 넣어주는 것이다.
(대충 AbstractPagingItemReader의 동작 방법이 results에 주입된 값을 return 하는 형식인 거 같다)
마지막으로 findMaxId()라는 메서드를 이용하여 lastId를 select 한 값들 중에 가장 큰 ID 값으로 변경시켜 주는 것이다.
private void findMaxId(List<MemberDto> dtos) {
for (MemberDto dto : dtos) {
Long memberId = dto.getMemberId();
if (memberId != null && (lastId == null || memberId > lastId)) {
lastId = memberId;
}
}
}
Query를 통해 얻은 List를 넘겨 반복문을 돌고 가장 큰 memberId를 lastId로 설정하게 되는 것이다.
여기까지가 구현한 CustomItemReader이고 해당 Reader 를 사용할 땐
@Bean
@StepScope
public CustomItemReader memberReader() {
return new CustomItemReader(entityManager, chunkSize, null);
}
위와 같이 사용하면 되는 것이다.
여기서 두 번째, 마지막으로 넘기는 파라미터 chunkSize, null은 각각 pageSize, lastId가 된다.
이제 동작 방식을 생각해 보면
CustomItemReader는 chunkSize 씩 데이터를 Read 하는데 (chunkSize = pageSize)
초기에 null을 넘기면 containLastId() 를 통해서 member.id > 0 라는 조건으로 Read 하게 된다.
그렇게 chunkSize 만큼의 데이터를 return 하고 lastId 에는 findMaxId() 를 통해 Read 한 데이터 중 가장 큰 ID 값을 설정하게 된다.
이렇게 한 번의 Read가 실행되고 다음 다시 Read를 하게 되면 lastId는 null이 아니기 때문에 containLastId() 를 통해서 member.id > lastId 라는 조건으로 Read 하게 된다.
위의 과정이 반복되게 되는 것이다.
여기서 중요한 것이 이렇게 데이터를 Read하면 Offset은 항상 0으로 고정 되고 Limit은 chunkSize로 고정되는 것이다.
따라서 offset이 커지면서 늘어나는 비용을 없앨 수 있는 것이다.
아래는 테스트 결과이다.

1,000건의 데이터를 처리할 땐 크지 않다고 생각한 처리 시간이 500,000건의 데이터에선 큰 차이를 보이고 있다.
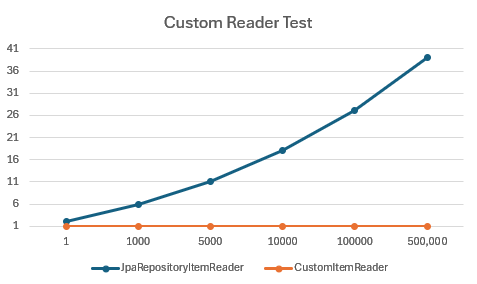
JpaRepositoryItemReader는 1번째 Data를 Read 할 땐 1초가 걸리지 않았지만 500,000번째 Data를 Read 할 땐 41초 가까이 걸렸다.
하지만 CustomItemReader는 1번째 Data나 500,000번째 Data나 동일하게 1초가 걸리지 않았다.
Offset이 늘어나지 않았기 때문이다.
'Web > Spring' 카테고리의 다른 글
| [Spring Batch] Batch Performance 성능 향상 (0) | 2024.04.30 |
|---|---|
| [Spring] 파일 업로드/다운로드 (다운로드) (0) | 2024.04.08 |
| [Spring] 파일 업로드/다운로드 (업로드) (0) | 2024.04.08 |
| Spring Open Feign 녀석을 만났다. (0) | 2024.03.04 |
| 맨땅에 Spring Batch - 회원 복제 (0) | 2024.01.16 |
